Un Solo Agente Para Dominarlos a Todos: Cuando Más Agentes No Significa Más Inteligencia
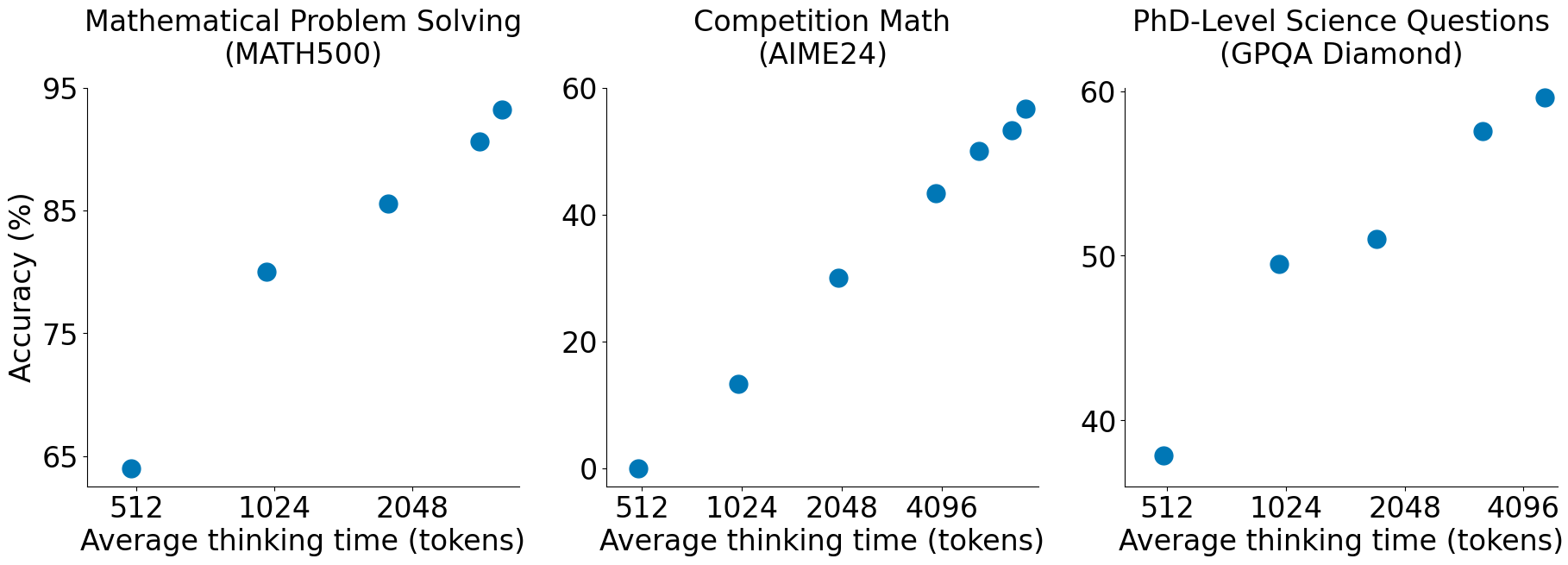
Un nuevo paper de arXiv (2604.02460) demuestra que los sistemas multi-agente LLM no son intrínsecamente superiores a los de un solo agente. Con presupuestos de tokens igualados, un único agente iguala o supera a arquitecturas de múltiples agentes en razonamiento multi-hop. La superioridad aparente de los sistemas multi-agente era, en muchos casos, un artefacto de cómputo no contabilizado.