Paper Destacado: DeepSeek-R1 Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Autores: DeepSeek-AI
Publicación: 22 de enero, 2025
GitHub: deepseek-ai/DeepSeek-R1 ⭐ 91.8k stars
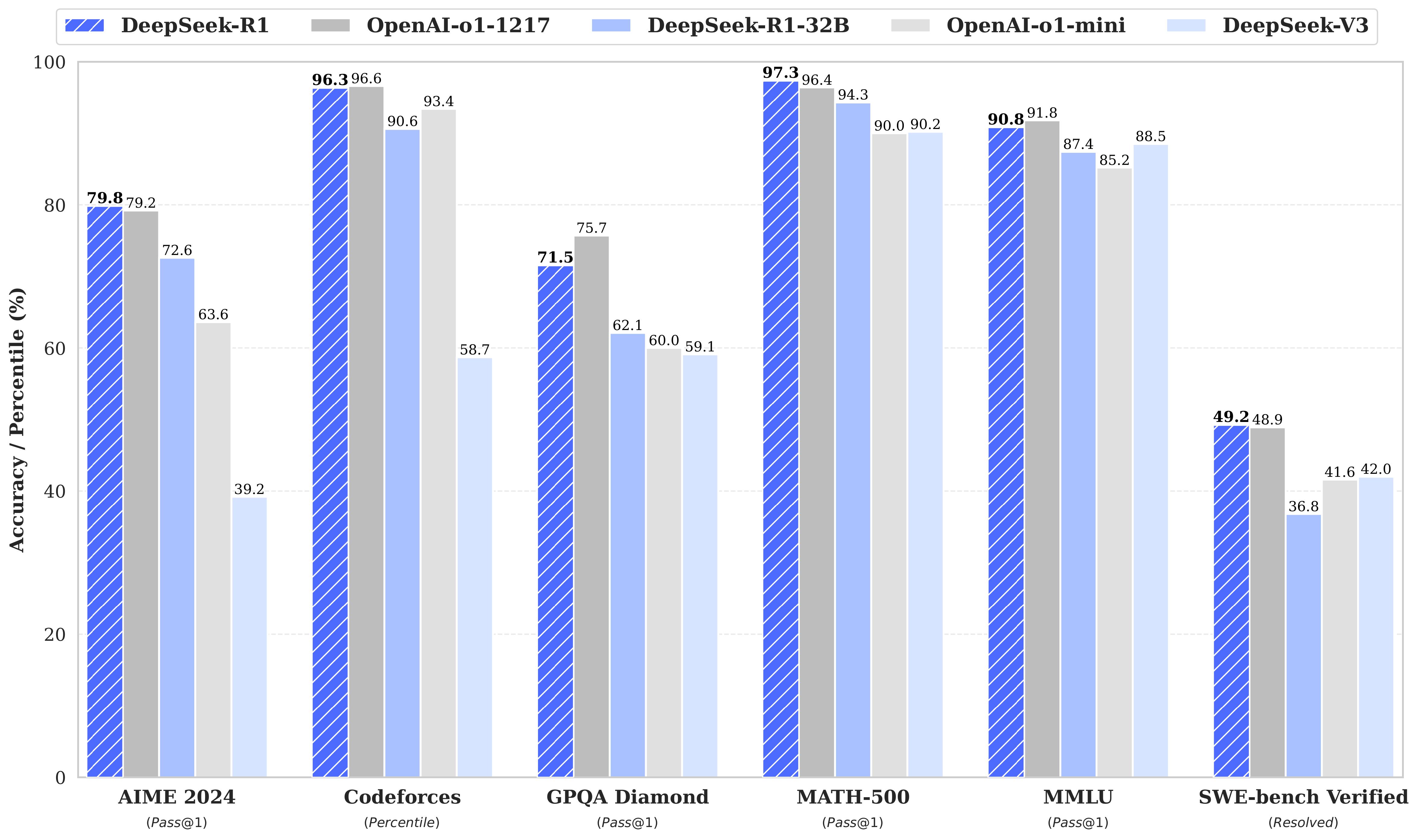
¿Por qué es importante este paper? DeepSeek-R1 representa un hito fundamental en el desarrollo de modelos de razonamiento. Por primera vez, se demuestra que un LLM puede desarrollar capacidades de razonamiento robustas sin necesidad de supervised fine-tuning inicial, utilizando únicamente reinforcement learning (RL) a gran escala.
Impacto en la industria Open Source Total: A diferencia de GPT-o1, DeepSeek-R1 es completamente open-source, democratizando el acceso a modelos de razonamiento avanzado Eficiencia Demostrada: Logra performance comparable a OpenAI o1-1217 con una arquitectura y metodología transparente Adopción Masiva: 91.8k estrellas en GitHub en menos de 10 días evidencian el interés de la comunidad Contribuciones Clave 1. DeepSeek-R1-Zero: RL Puro El modelo DeepSeek-R1-Zero se entrena exclusivamente con reinforcement learning, sin ningún fine-tuning supervisado previo. Los resultados son sorprendentes:
...