s1: Escalando el Razonamiento con Solo 1,000 Ejemplos y 'Budget Forcing'
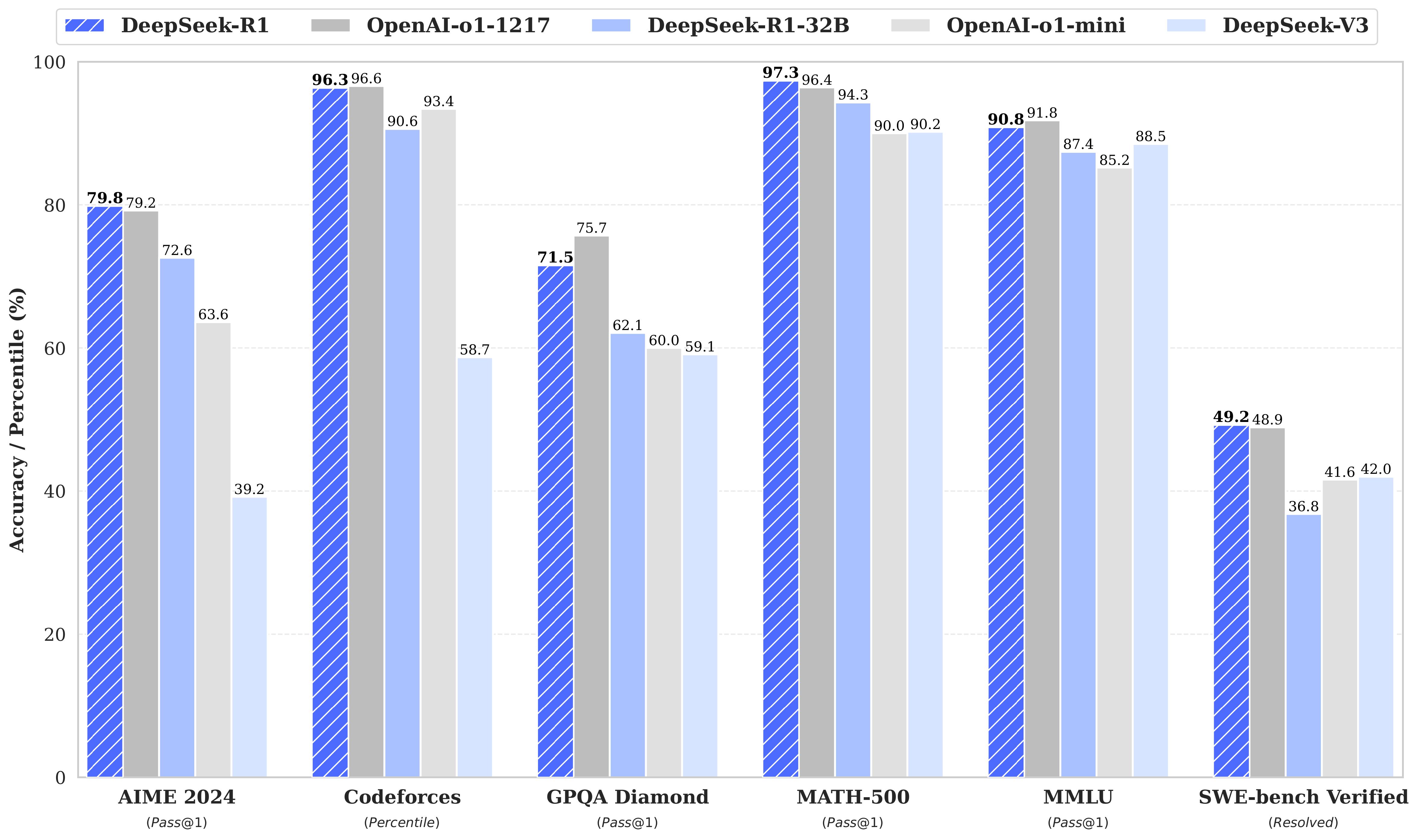
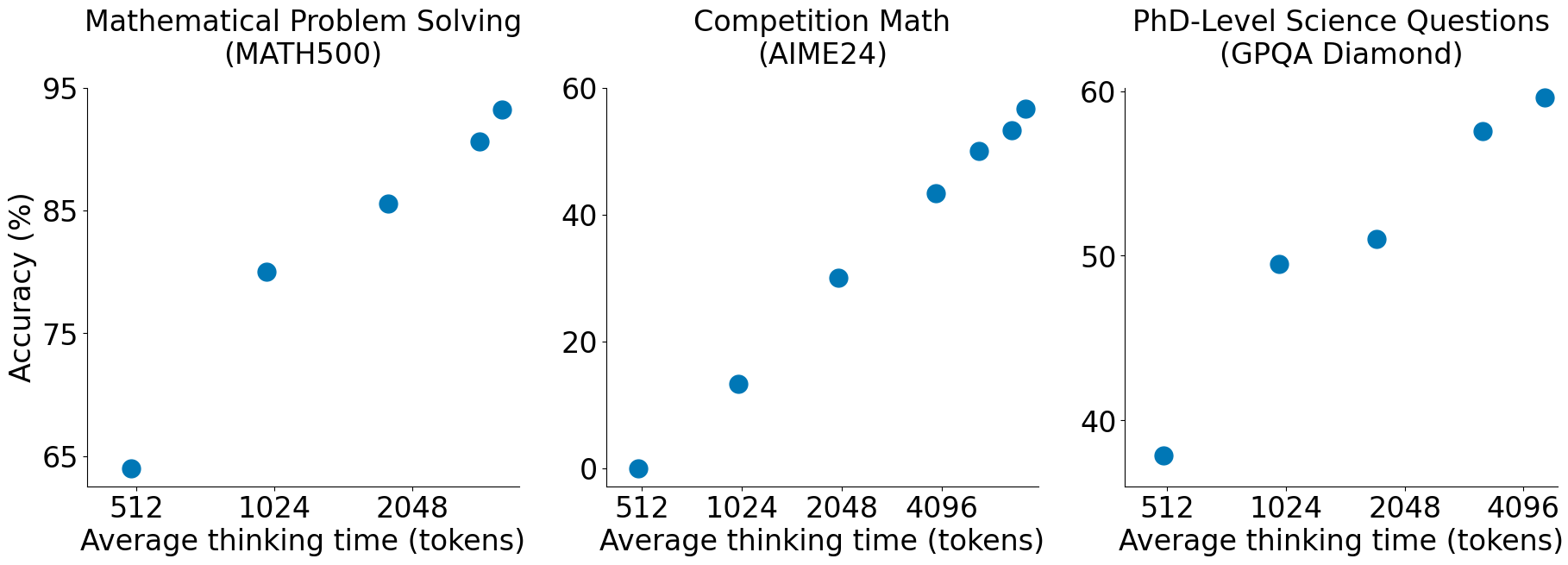
Paper de la Semana: s1 (Simple Test-Time Scaling) Paper: s1: Simple test-time scaling Autores: Muennighoff et al. (simplescaling) Publicación: Enero 2026 GitHub: simplescaling/s1 ¿Por qué es relevante? Mientras todos persiguen datasets masivos y clusters de entrenamiento gigantescos, s1 llega con una premisa rompedora: puedes lograr capacidades de razonamiento de vanguardia (SOTA) con solo 1,000 ejemplos de entrenamiento cuidadosamente curados. Este paper desafía la noción de que el razonamiento avanzado es una propiedad emergente exclusiva de modelos entrenados con RL a gran escala (como DeepSeek-R1 o OpenAI o1). En su lugar, demuestran que un modelo fuerte (Qwen2.5-32B) puede “desbloquear” estas capacidades mediante: ...