Paper de la Semana: s1 (Simple Test-Time Scaling)
Paper: s1: Simple test-time scaling
Autores: Muennighoff et al. (simplescaling)
Publicación: Enero 2026
GitHub: simplescaling/s1
¿Por qué es relevante?
Mientras todos persiguen datasets masivos y clusters de entrenamiento gigantescos, s1 llega con una premisa rompedora: puedes lograr capacidades de razonamiento de vanguardia (SOTA) con solo 1,000 ejemplos de entrenamiento cuidadosamente curados.
Este paper desafía la noción de que el razonamiento avanzado es una propiedad emergente exclusiva de modelos entrenados con RL a gran escala (como DeepSeek-R1 o OpenAI o1). En su lugar, demuestran que un modelo fuerte (Qwen2.5-32B) puede “desbloquear” estas capacidades mediante:
- Un dataset minúsculo pero de altísima calidad (s1K).
- Una técnica de inferencia inteligente llamada Budget Forcing.
Impacto
- Democratización: Reduce drásticamente la barrera de entrada para crear modelos de razonamiento.
- Eficiencia: Muestra que la calidad del dato > cantidad (por varios órdenes de magnitud).
- Control: Introduce una forma determinista de controlar cuánto “piensa” el modelo.
La Técnica: Budget Forcing
La innovación central no es el modelo, es el método de control durante la inferencia.
El Problema
Los modelos de razonamiento actuales (CoT) suelen tener una longitud de pensamiento variable e incontrolable. A veces piensan demasiado poco (fallan en problemas difíciles) o entran en bucles (fallan por incoherencia).
La Solución: Budget Forcing
El método es sorprendentemente simple y efectivo:
- Suprimir el token de fin: Evitan que el modelo deje de generar “pensamientos” prematuramente.
- Inyectar “Wait”: Si el modelo intenta terminar, le insertan el texto “Wait,” forzándolo a seguir razonando.
- Terminación forzada: Cortan el pensamiento cuando se alcanza el presupuesto de cómputo deseado.
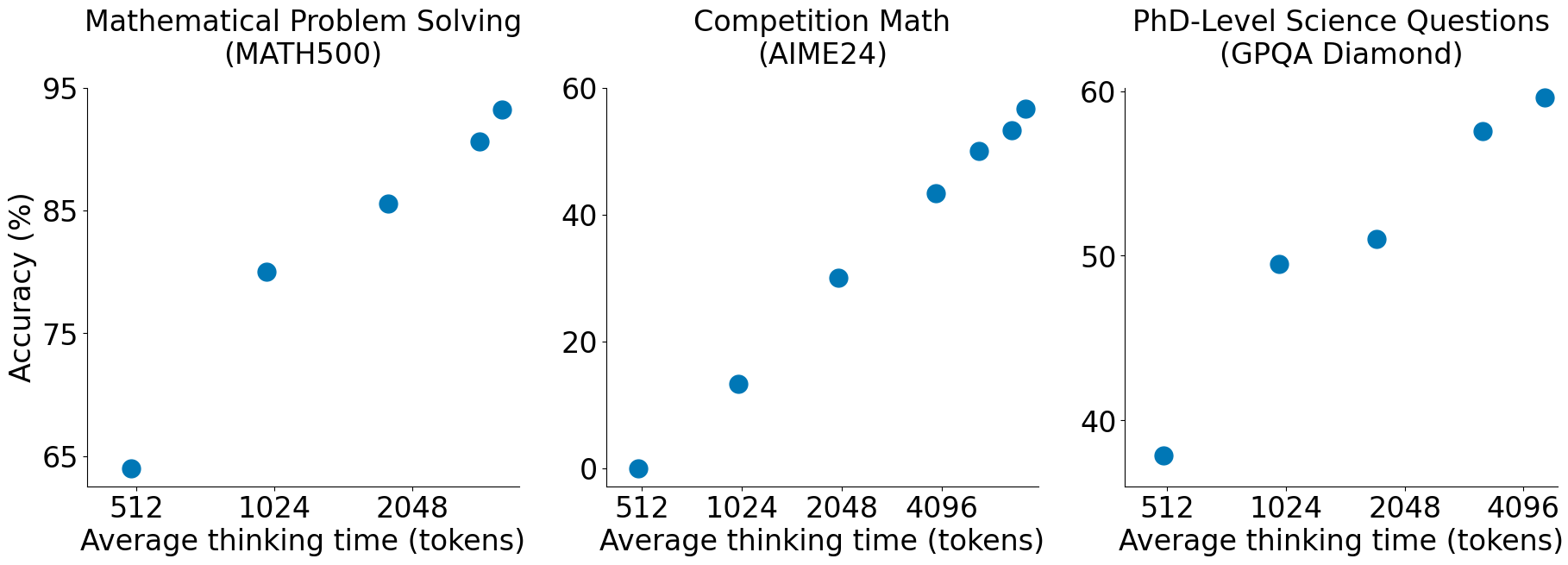
Esto permite Test-Time Scaling real:
“Más cómputo en inferencia = Mejor performance, de forma lineal y predecible.”
Resultados Clave
El modelo resultante, s1-32B, logra resultados impresionantes:
- Supera a o1-preview en benchmarks matemáticos difíciles como AIME24 y MATH500.
- 30% mejor que baselines entrenados con métodos tradicionales de selección de datos.
- Eficiencia extrema: Entrenado con solo 1,000 ejemplos, frente a los decenas de miles o millones usados habitualmente.
| Modelo | AIME24 Accuracy | Método |
|---|---|---|
| s1-32B | 56.7% | Budget Forcing + s1K |
| Qwen2.5-32B | ~30% | Base Instruct |
| TCC Baseline | 40.0% | Control condicional |
Insights para Ingenieros
1. Calidad > Cantidad (Extremo)
El dataset s1K fue creado filtrando 59,000 preguntas para quedarse solo con 1,000. Los criterios fueron:
- Dificultad: Solo problemas que requieren cadenas de pensamiento largas.
- Diversidad: Cubrir múltiples dominios para evitar overfitting.
- Calidad: Trazas de razonamiento verificadas y limpias.
Lección: Si estás haciendo fine-tuning, dedica el 90% del tiempo a limpiar tus datos, no a ajustar hiperparámetros.
2. Inferencia Dinámica
El concepto de “Budget Forcing” sugiere que en producción no deberíamos tratar todas las queries igual.
- Queries simples -> Presupuesto bajo (respuesta rápida/barata).
- Queries complejas -> Presupuesto alto (forzar “Wait”, más tokens, mejor respuesta).
Conclusión
s1 es un recordatorio de que la fuerza bruta no es el único camino en IA. A veces, una idea inteligente (controlar el token de parada) y una curación de datos obsesiva valen más que 1,000 GPUs.
Para los que construimos sistemas, esto abre la puerta a tener “modelos de razonamiento” especializados y controlables, sin depender de cajas negras gigantes.
¿Te ha parecido interesante este enfoque minimalista?