Paper de la Semana: OpenScholar
- Paper: OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
- Autores: Asai et al. (Allen AI, UW)
- Publicación: 21 de noviembre, 2025 (Trending early Dec)
- GitHub: AkariAsai/OpenScholar
¿Por qué es relevante?
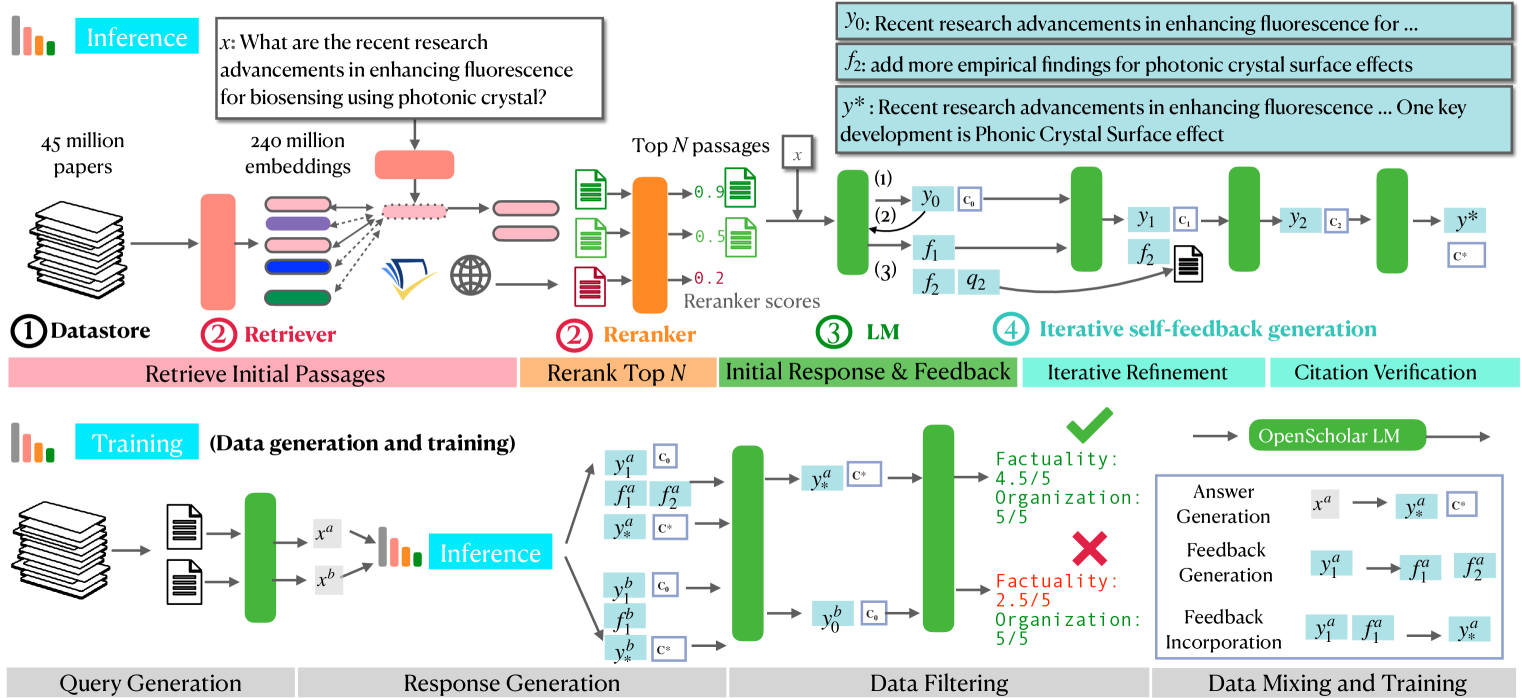
Los LLMs genéricos alucinan. Y cuando alucinan sobre referencias científicas, el problema es grave. OpenScholar aborda esto frontalmente. No es solo otro chatbot; es un sistema RAG especializado conectado a un datastore masivo de 45 millones de papers de acceso abierto. En benchmarks de preguntas científicas (ScholarQABench), un modelo OpenScholar-8B supera a GPT-4o, demostrando que el contexto adecuado vale más que el tamaño del modelo.
Detalles Técnicos
La arquitectura de OpenScholar se centra en la recuperación iterativa y la auto-refinación:
- Retrieval-Augmented: Utiliza un índice denso de 45M de documentos científicos.
- Iterative Refinement: Cuando se le hace una pregunta compleja, el modelo no busca una sola vez. Realiza múltiples pasos de búsqueda, evaluando si la información encontrada es suficiente o si necesita profundizar en citas específicas.
- Self-Correction: El modelo está entrenado para citar sus fuentes con precisión a nivel de párrafo. Si genera una afirmación que no está respaldada por el paper recuperado, su mecanismo de feedback interno penaliza esa generación.
- Model Distillation: Demostraron que pueden destilar el rendimiento de modelos propietarios gigantes en un modelo Llama-3-8B abierto, haciéndolo accesible para laboratorios universitarios.
Opinión
OpenScholar es un vistazo al futuro de la investigación académica asistida. Ya no se trata de pedirle a ChatGPT que “invente” una respuesta plausible, sino de tener un asistente que lee literalmente millones de papers en segundos y te dice: “Según Smith et al. (2024), esto funciona así…”. Para la comunidad científica, esto es oro puro.