Paper Destacado: DeepSeek-R1
Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Autores: DeepSeek-AI
Publicación: 22 de enero, 2025
GitHub: deepseek-ai/DeepSeek-R1 ⭐ 91.8k stars
¿Por qué es importante este paper?
DeepSeek-R1 representa un hito fundamental en el desarrollo de modelos de razonamiento. Por primera vez, se demuestra que un LLM puede desarrollar capacidades de razonamiento robustas sin necesidad de supervised fine-tuning inicial, utilizando únicamente reinforcement learning (RL) a gran escala.
Impacto en la industria
- Open Source Total: A diferencia de GPT-o1, DeepSeek-R1 es completamente open-source, democratizando el acceso a modelos de razonamiento avanzado
- Eficiencia Demostrada: Logra performance comparable a OpenAI o1-1217 con una arquitectura y metodología transparente
- Adopción Masiva: 91.8k estrellas en GitHub en menos de 10 días evidencian el interés de la comunidad
Contribuciones Clave
1. DeepSeek-R1-Zero: RL Puro
El modelo DeepSeek-R1-Zero se entrena exclusivamente con reinforcement learning, sin ningún fine-tuning supervisado previo. Los resultados son sorprendentes:
- Comienza con 15.6% de accuracy en AIME 2024
- Alcanza 71.0% usando solo RL
- Rivaliza con OpenAI o1-0912 en problemas matemáticos complejos
Limitaciones emergentes: El modelo desarrolla problemas de legibilidad y mezcla de idiomas, que son abordados en la siguiente fase.
2. Pipeline de Entrenamiento Multi-Etapa
DeepSeek-R1 refina el enfoque con un pipeline sofisticado:
- Etapa RL 1: Descubrimiento de patrones de razonamiento
- Etapa SFT 1: Cold-start data para sembrar capacidades básicas
- Etapa RL 2: Alineación con preferencias humanas
- Etapa SFT 2: Refinamiento de capacidades no relacionadas con razonamiento
Este enfoque híbrido resuelve los problemas de legibilidad mientras mantiene las capacidades de razonamiento emergentes.
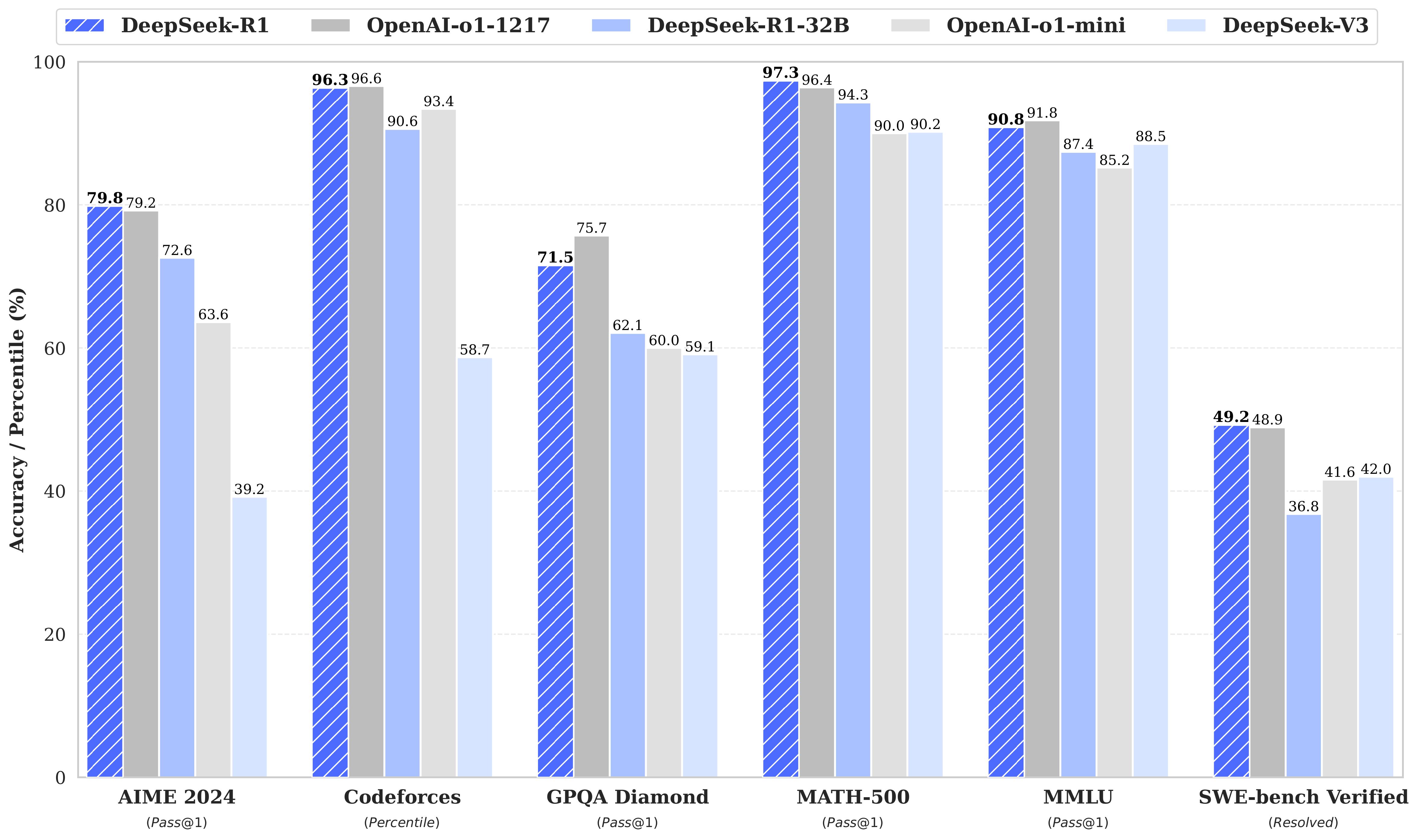
3. Resultados Benchmark Excepcionales
DeepSeek-R1 iguala o supera a OpenAI o1-1217 en múltiples benchmarks:
| Benchmark | DeepSeek-R1 | OpenAI o1-1217 | DeepSeek-V3 |
|---|---|---|---|
| AIME 2024 | 79.8% | 79.2% | 39.2% |
| MATH-500 | 97.3% | 96.4% | 90.2% |
| MMLU | 90.8% | 89.2% | 88.5% |
| GPQA Diamond | 71.5% | 75.7% | 59.1% |
| Codeforces | 2029 rating | - | 1450 rating |
| AlpacaEval 2.0 | 87.6% | - | 70.5% |
Destaca especialmente en:
- Tareas matemáticas complejas
- Competencias de programación (Codeforces expert-level)
- Benchmarks de razonamiento general
4. Distillation en Modelos Pequeños
DeepSeek-R1 demuestra que el razonamiento puede destilarse efectivamente en modelos más pequeños:
- Liberan 6 modelos distilados (1.5B a 70B parámetros)
- Basados en arquitecturas Qwen y Llama
- Superan el RL directo en modelos pequeños
- Permiten razonamiento avanzado en hardware limitado
Insights Técnicos
Arquitectura MoE (Mixture of Experts)
DeepSeek-R1 utiliza una arquitectura MoE con:
- 145B parámetros totales
- 2.8B parámetros activos por token
- Eficiencia computacional superior a modelos densos equivalentes
Proceso de Reinforcement Learning
El entrenamiento por RL permite que el modelo:
- Explore estrategias de resolución sin guías explícitas
- Desarrolle chain-of-thought de forma emergente
- Auto-corrija errores durante el razonamiento
- Optimice para accuracy en lugar de imitar patrones
Esta aproximación contrasta con el fine-tuning tradicional y resulta en capacidades de razonamiento más robustas.
Implicaciones para Developers
¿Cuándo usar DeepSeek-R1?
✅ Ideal para:
- Problemas matemáticos complejos
- Tareas de programación avanzada
- Razonamiento lógico multi-paso
- Análisis que requiere verificación
⚠️ Considera alternativas para:
- Tareas simples de generación de texto
- Respuestas rápidas sin razonamiento
- Escenarios con latencia crítica
Integración Práctica
# Ejemplo usando la API de DeepSeek
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "Resuelve: Si x^2 + y^2 = 25 y x + y = 7, ¿cuál es xy?"}
]
)
print(response.choices[0].message.content)
Mirando al Futuro
DeepSeek-R1 abre varias líneas de investigación:
- RL como paradigma principal: ¿Puede RL reemplazar al supervised fine-tuning?
- Escalabilidad: ¿Qué sucede con modelos aún más grandes entrenados con RL?
- Generalización: ¿Las capacidades de razonamiento se transfieren a otros dominios?
- Eficiencia: ¿Pueden los modelos distilados alcanzar el mismo nivel?
Referencias y Recursos
- Paper: https://arxiv.org/abs/2501.12948
- Repositorio GitHub: https://github.com/deepseek-ai/DeepSeek-R1
- Modelos en HuggingFace: https://huggingface.co/deepseek-ai
- API Documentation: https://api-docs.deepseek.com/
Conclusión
DeepSeek-R1 demuestra que el reinforcement learning puro puede producir capacidades de razonamiento comparables a los modelos propietarios más avanzados. Su naturaleza open-source y los modelos distilados lo convierten en una herramienta accesible para desarrolladores y investigadores.
La comunidad ya está construyendo sobre esta base: reproducciones independientes, integraciones en frameworks populares, y experimentos con técnicas híbridas. Este es el momento de experimentar.
¿Has probado DeepSeek-R1? Comparte tu experiencia.
Etiquetas: #AI #MachineLearning #ReinforcementLearning #OpenSource #LLMs #DeepSeek